CyberConnect's NFT Recommendation Engine
An Introduction

Introduction
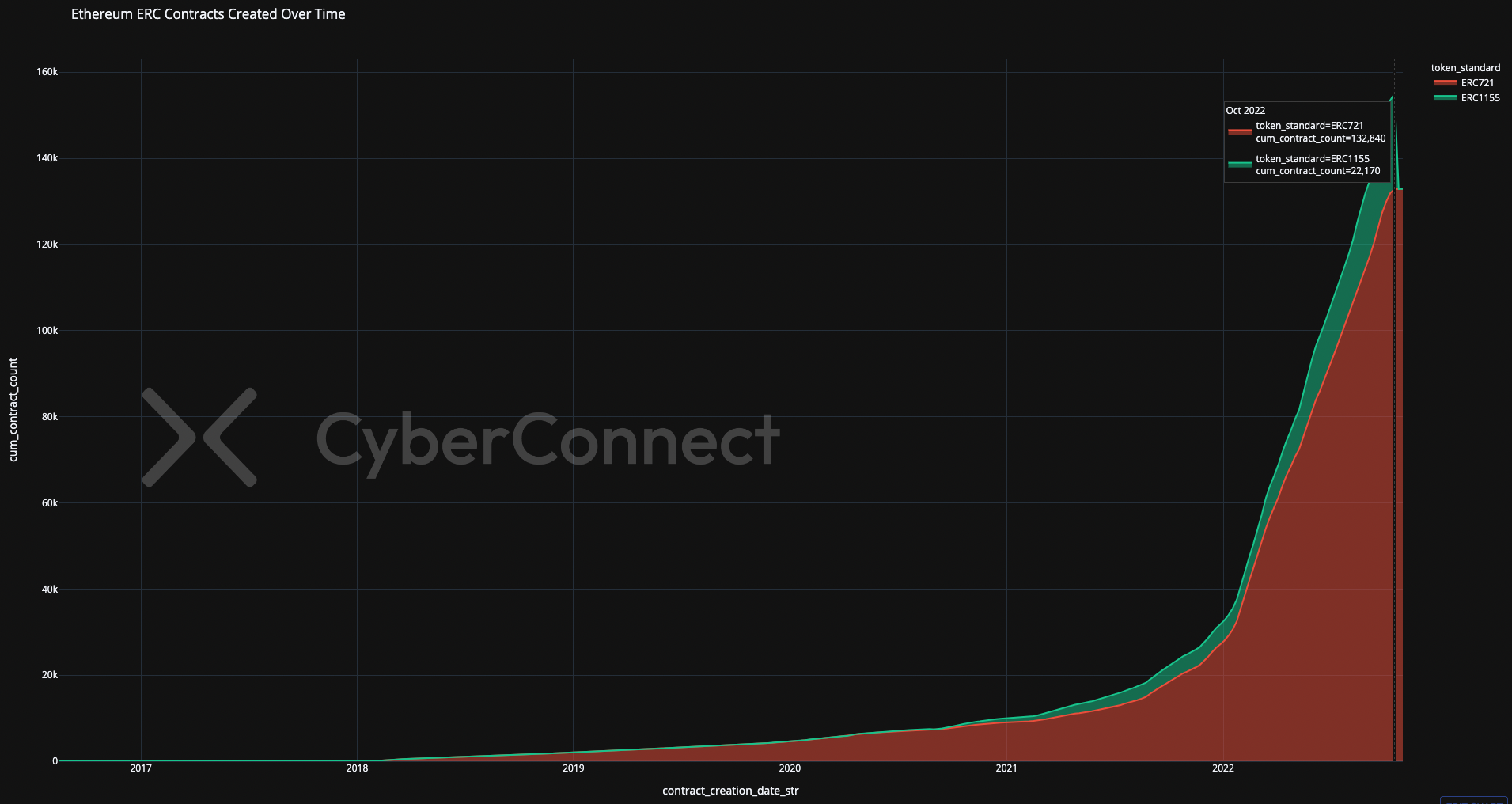
Discovering new projects in Web3 is incredibly challenging. Whether you’re trying to stay up to date with the latest NFT PFP projects or looking to discover the latest on-chain games - Web3 in its current state lacks a way to discover personalized content and projects that cater to your interests. In fact, on-chain discovery today feels very much like online product discovery in the late 1990s. We either hear about online products from friends and family (crypto Twitter today) or we log on to an online marketplace and are presented with a list of non-personalized/general products (front page of OpenSea). Although there are services like Icy Tools and Rarity Tools, they cater more to the traders rather than the collectors. Their focus is on generating profit for their users rather than artistic/social discovery. Most people aren’t traders, nor are they interested in making money off of monkey pictures. People browse the web to discover content, ideas & people that they can connect with. The relevance individual users are looking for is largely lacking in current Web3. Over 100,000 ERC-721 contracts have already been deployed on Ethereum alone and as hundreds more go live every week, this discovery problem is only getting exponentially more difficult.
CyberConnect is a decentralized social network protocol helping developers build the next generation of social dApps by providing state-of-the-art Web3-native tooling and infrastructure. We believe that helping solve the problem of NFT discovery is a key component within that toolkit.
Social dApps and NFT Discovery
Web3 and decentralized social are fundamentally user-centric. Users own and take their social connections, preferences, histories, and in all their holistic identities across different platforms and contexts. The social experience of this next iteration of the internet should always seamlessly and consistently cater to the users’ preferences, instead of being siloed by platform walls. Core to this experience is a new mechanism for users to discover content and projects that are more meaningfully connected to their identity and values.
To help with this growing discovery problem, our team at CyberConnect is developing a suite of recommendation engines for Web3 that can be leveraged across social, DeFi, and all other projects looking to incorporate decentralized social into their services. Today we’re excited to launch the first version of our NFT discovery/recommendation engine: our first step in helping both developers & users in discovering new ERC-721/1155 projects that they might be interested in based on their on-chain activity.
More generally, we’re developing a suite of recommendation engines for Web3 that can be leveraged across social dApps, DeFi protocols, or any other project looking to incorporate decentralized social into their product.
CyberConnect Recommendation Engine
This model provides two main recommendation endpoints:
userRecommendation= Recommends user addresses (EOAs) that have similar NFT trading history as an input address.tokenRecommendation= Recommends ERC-721 tokens that are similar to an input address’ NFT history .
1. userRecommendation Endpoint Walkthrough
Here’s a sample query for userRecommendation endpoint using Bankless Co-Founder David Hoffman‘s ETH address (0xfA53D837B5dDd616007F91487F041d27edb683A0)
Query Template
query getUserRecommendatio($address: AddressEVM!, $chainId: ChainID!) {
address(address: $address) {
wallet {
recommendation (chainID: $chainId) {
userRecommendation {
userToFollow
userToFollowRank
userToFollowDistanceScore
userToFollowReason
}
}
}
}
}
Sample Response
{
"data": {
"address": {
"ethWallet": {
"recommendation": {
"userRecommendation": [
{
"userToFollow": "0x7ec6ffd8c5d5620903a22ce7a8b37d62e0e6559a",
"userToFollowRank": 1,
"userToFollowDistanceScore": 2.5657267570495605,
"userToFollowReason": "Similar ERC721 Trading History"
}, ...
Looking at the first recommendation, we get this address 0x7ec6ffd8c5d5620903a22ce7a8b37d62e0e6559a`
Upon searching for said address on OpenSea, we find out that that this output address is actually owned by logancraig.eth, visual designer at Bankless! Note that even though the recommendation model had no information on the users’ off-chain details, it was able to identify a co-worker purely based on NFT trading history!
2. tokenRecommendation Endpoint Walkthrough
Now let’s run through an example of the second endpoint - tokenRecommendation . This time let’s use David's co-host Ryan Sean Adam‘s ETH address -> 0xE9D18dbFd105155eb367fcFef87eAaAFD15ea4B2.
Query Template
query GetTokenRecommendation($address:AddressEVM!, $chainId: ChainID!)
{
address(address: $address) {
wallet {
recommendation (chainID: $chainId) {
tokenRecommendation {
rank
tokenInfo {
token {
... on ERC721 {
name
symbol
contractAddress
}
}
tokenLogo
twitter
homepage
etherscan_labels
etherscan_token_contractnames
}
}
}
}
}
}
Sample Response
{
"data": {
"address": {
"wallet": {
"recommendation": {
"tokenRecommendation": [
{
"rank": 0,
"tokenInfo": {
"token": {
"name": "The Infinite Machine Movie Collection",
"symbol": "INFINITE",
"contractAddress": "0x674d37ac70e3a946b4a3eb85eeadf3a75407ee41"
},
"tokenLogo": "https://lh3.googleusercontent.com/UsX1WeoXvor4nxN0ssF39r7y2cg4N2yrus7qilzodPtB7KtnwCBf-TaEU2-9VPPsscmgYwjSsQPJBdDqG04djxW3YVXu3ppYEtoK=s120",
"twitter": "https://twitter.com/ETHMovie",
"homepage": "https://www.theinfinitemachinemovie.com/",
"etherscan_labels": [
"Token Contract"
],
"etherscan_token_contractnames": []
}
},
{
"rank": 1,
"tokenInfo": {
"token": {
"name": "DAOpunks",
"symbol": "DAOPNK",
"contractAddress": "0x700f045de43fce6d2c25df0288b41669b7566bbe"
},
"tokenLogo": "https://lh3.googleusercontent.com/fpyFlFiwfJTe2_lD00907R-X9ZheiUcw4Pyuyz9vrDfLXHEIFBS3qP18DqfoWZIOkJl95FZw9nsR7vfN3xXJkJBLO9ZZZVRwJWSJ=s120",
"twitter": "https://twitter.com/DAOpunksNFT",
"homepage": "https://daopunks.io",
"etherscan_labels": [],
"etherscan_token_contractnames": []
}
},
{
"rank": 2,
"tokenInfo": {
"token": {
"name": "The Rocketeers",
"symbol": "RCT",
"contractAddress": "0xb3767b2033cf24334095dc82029dbf0e9528039d"
},
"tokenLogo": "https://lh3.googleusercontent.com/KsAt3pNG_NNHwTPU3OeVS175wX0M-4PrrjACMSI6A-dwmejWvMr68_sS7MiNk_aaDDDsKqcZNaUkYVlCYo9iAnlz7IheXXeenDt9Ik4=s120",
"twitter": "",
"homepage": "https://rocketeer.fans/",
"etherscan_labels": [],
"etherscan_token_contractnames": []
}
},
The Top 3 Recommended Tokens are:
- An NFT supporting the making of a movie about Ethereum - very inline with Ryan's support for the ethereum community!
Ryan actually follows the project on twitter!
- Ryan is a strong supporter of rocket pool and "Rocketeers are the unofficial spirit animals of the Rocketpool staking community,..."
Admittedly, it’s hard to predict whether Ryan himself would like or want to buy these NFTs, but these recommendations directionally make sense.
P.S. Ryan, if you’re reading this article, we’d love to know what you think of these recommendations :)
How Do Most Recommendation Models Work?
While there are several approaches to recommendation systems, they are usually divided into two broad categories: collaborative and content-based filtering.
According to Wikipedia:
Collaborative filtering approaches build a model from a user’s past behavior (items previously purchased or selected and/or numerical ratings given to those items) as well as similar decisions made by other users. Content-based filtering approaches utilize a series of discrete characteristics of an item in order to recommend additional items with similar properties.
For NFTs in particular, it’s hard to apply a content-based approach because measuring similarity between NFTs is more complex than most might assume. While one could compare two NFTs’ metadata, and if they both indeed share the same trait, are they necessarily similar? What if a collection is merely trying to copy the traits/metadata of another in an attempt to attract the user base of a more prominent, successful collection?
While our team at CyberConnect does plan on building hybrid recommendation models in the future, we decided to start with collaborative filtering (CF). But there’s a caveat. Standard collaborative filtering is based on user ratings (like Netflix), however, with NFTs, there are no reliable user ratings. Thankfully there’s an alternative. Even if people are not rating content, implicit feedback can be more than enough:
Implicit feedback is user activity that can be used to indirectly infer user preferences, e.g. clicks, page views, purchase actions. Sometimes only positive feedback is known, e.g. the products customers have bought, but not the ones they have decided against.
In this case, we use implicit feedback in the form of NFT purchases, mints & transfers and then we can use apply the Collaborative Filtering for Implicit Feedback factor model implementation to derive generate useful recommendations. from that implicit feedback.
Making Sense of CyberConnect Recommendation Engine
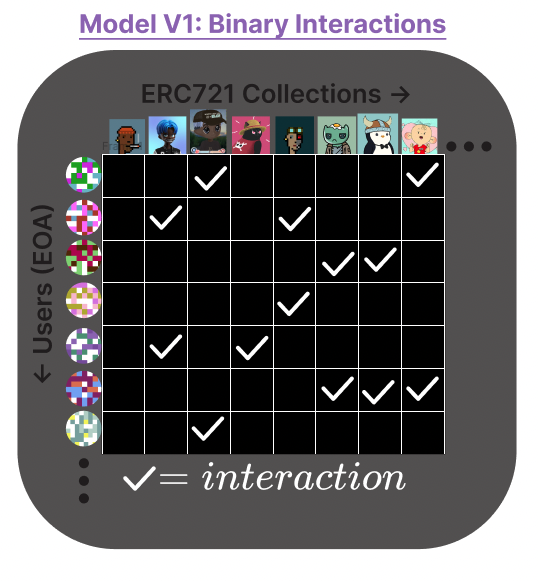
Let’s get more concrete about how our collaborative filtering model was built. Consider the following feedback matrix, in which:
Each row represents a user address (i.e. EOA)
Each column represents an NFT contract/project
In the simplest case, the feedback about NFTs from users could be binary; that is, a value of 1 indicates the user interacted with the NFT contract, 0 indicates no interaction. Populating our matrix would give us a large (specifically size # of users * # of nft addresses) matrix filled with 1s and 0s (mostly 0s since most people only own a very small % of all available nfts). We’d then factorize the matrix and only keep the top n columns/features such that we can describe every user as a vector of n numbers.
Matrix factorization is a simple embedding model. Given the feedback matrix \(A∈R^{m×n}\), where $m$ is the number of users (or addresses) and $n$ is the number of items (or nft contracts), the model learns:
An address embedding matrix , where row $i$ is the embedding for user $i$.
\(U∈R^{m×d}\)
A contract embedding matrix , where row $j$ is the embedding for contract $j$.
\(V∈R^{n×d}\)
The embeddings are learned such that the product \(UV^T\) is a good approximation of the feedback matrix A. Observe that the $(i,j)$ entry of \(U^.V^T\) is simply the dot product $⟨Ui,Vj⟩$ of the embeddings of user $i$ and item $j$, which you want to be close to \(A_{i,j}\). The key piece here is that matrix factorization typically gives a more compact representation than learning the full matrix. The full matrix has $O(nm)$ entries, while the embedding matrices $U, V$ have \(O((n+m)d)\) entries, where the embedding dimension $d$ is typically much smaller than $m$ and $n$. As a result, matrix factorization finds latent structure in the data, assuming that observations lie close to a low-dimensional subspace. So in our case, there are on the order of ~5M addresses that have interacted with ERC-721s on ETH L1, and ~120k different ERC-721s. That means the full matrix 5M x 120k ~600,000,000,000 pair/cells, so factorization of this matrix was necessary to build a scalable and fast recommendation model. Once the matrix is factorized (using one of the many factorization algorithms), we’re left with user/address vectors & nft/contract vectors. With those we can then easily find similar users and/or nfts based on calculating the distances between those vectors using a distance function (ex. cosine similarity, euclidean distance, etc.)
Up until here this has all been standard collaborative filtering, with the caveat that we’re using ERC-721 interaction data rather than movie ratings, or youtube views. There are a few particular insights and improvements we had in building our specific ERC-721 recommender:
- Filtering out spam collections
This was the most impactful improvement to our recommendations. We initially trained a model using all ~120k ERC-721 contracts but found that the model kept recommending poor quality NFT projects/airdrops/spam collections. So we spent a good amount of time aggregating verified NFT contract lists from several sources (including Opensea, Trustwallet, Dune, Alchemy, etc.) and also applied custom logic to filter collections with certain airdrop-like behavior. This reduced the number of contracts significantly and improved the quality of our recommendations.
- Not treating all interactions as equal
The second insight we had was that of using our domain knowledge in NFTs to replace the implicit interaction counts with weighted composite scores. Specifically, we applied specific weights to different kinds of interactions with NFTs (ex. mints, burns, etc.) to more accurately summarize the users’ history of implicit interactions with a contract. That can be seen in the last image below where the checkmarks ✔️ are replace with $f(mints,burns,trades, etc)$.
- Including Exchange Contract/Trades
The last change we made was to incorporate data/signal from which NFT marketplace the transfer/mint/burn occurred. This was valuable in improving the recommendations since some users only buy/sell from one marketplace (ex. Rarible), so giving weight to that information means that two Rarible power users will get more similar vectors (& hence recommendations) than if we just looked at NFT contract information alone.
Combining the above three modifications resulted in a recommendation engine that was significantly more accurate than those using a standard collaborative filtering matrix factorization.

Conclusion
We’re still only at the beginning of the transition from a centralized & siloed web to a decentralized user-centric one. A large part of this consists of a new mechanism of content discovery & recommendations. Our first contribution to this transitioning is this ERC-721-based recommendation model and it is available today through both the API endpoints referenced above.
We’re just getting started with NFT recommendations and have plans to release additional models in the future. There’s a lot more that we want to do and the following are some of the things that we’re currently working on:
Adding support for other ERC standards
Including off-chain data on projects
Incorporating NFT Metadata to give more granular recommendations (eg. recommend specific NFT, rather than just the collection)
Adding support for additional chains
We’re excited to share more in the future and are always available to support developers who want to build applications that leverage our models. Get in touch if you would love to build together!
If you like what you read, subscribe to our newsletter, check out our Mirror and follow us on CyberConnect Twitter. Tempted to contribute? Check out this getting started with CyberConnect guide, join our vibrant community by clicking here or dive into our developer docs here.



